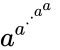In a previous post, I discussed
Really Big Numbers, moving from many children's example of a big number, a million, up past what most people I meet would think of as a huge number, a googol, and ultimately going through Graham's number, TREE(3), the busy beaver function, infinities and beyond. I wasn't aware of it at the time, but a much better version of that post already existed:
Who Can Name the Bigger Number?, by Scott Aaronson.
In my original post,
I made a few errors in the section about fast growing functions. Some kind commentors helped correct the most egregious errors, but the ensuing corrections littered that entire section of the post with strikethrough text that I was never really happy with. Now, six years later, I'd like to finally make up for my mistakes.
The Goal
I'd like to name some really, really big numbers. I'm not going to talk about the smaller ones, nor the ones that delve into infinities; you can read the previous post for that. Here I just want to point toward some really big finite numbers. The numbers I'm aiming for are counting numbers, like 1, 2, or a billion. They're not infinite in size. These are numbers where, if someone asked you to write a really, really big number, these would be way beyond what the questioner was thinking of, and yet still wouldn't be infinite in extent.
Why Functions?
We always use functions when writing numbers. It's just that most of the time, it's invisible to us. If we're counting apples, we might make a hatch mark (or tally mark) for the first apple, another hatch for the second ("‖"), and so on. This works fine for up to a dozen apples or so, but it starts to get pretty difficult to understand at a glance. You might fix this by making every fifth hatch cross over the previous four ("卌"), but you quickly run into a problem again if you get too many sets of five hatch marks.
It's easier to come up with a better notation, like using numerals. Now we can use "1" or "5", rather than actually write out all those hatch marks. Then we can use a simple function to make our notation easier to follow. The rightmost numeral is the ones place, then next to the left is the tens place, and the next to the left is the hundreds place, and so on. So "123" means (1*100)+(2*10)+(3*1). Of course, I'm being loose with definitions here, as I've written "100" and "10" using the very system I'm trying to define. Feel to replace with tally marks: 2*10 is ‖*卌卌.
As you can see, functions are integral parts of any notation. So when I start turning to new notations by using functions to describe them, you shouldn't act as though this is somehow fundamentally different from the notations that you likely already use in everyday life. Using Knuth arrow notation is no less valid for saying a number's name than writing "123". They're both just names that point at a specific number of tally marks.
Defining Operations
Let's start with addition. Addition is an operation, not a number. But it's easier to talk in terms of operations when you get to really big numbers, so I want to start here. We'll begin with a first approximation of a really big number: 123. In terms of addition, you might say it is 100+23, or maybe 61+62. Or you may want to break it down to its tally marks: 卌卌卌…卌⦀. This is all quite unwieldy, though. I'd prefer to save space when typing all this out. So let's instead use the relatively small example of 9, not 123. You might not think of 9 as a really big number, but we've only just started. The first function, F₁(x,y), involves taking the numeral X and doing whatever operation it is Y times.
In this series of functions, I'm always going to use 3 for both x and y to make things as simple as possible. F₁ is addition, so F₁(3,3)=3+3+3=9.
Each subsequent function Fₓ is just a repetition of the previous function. Addition is repeated counting, but when you repeat addition, that's just multiplication. So our second operation, multiplication, can be looked at as F₂=3*3*3=27.
(As an aside, a similar function to Fₓ(3,2) can be seen at the
On-Line Encyclopedia of Integer Sequences. Their a(n) is equivalent to our Fₓ(3,2), where x=n-1. So their a(2) is our F₁(3,2). You may also notice that F₂(3,2)=F₁(3,3), so although the OEIS sequence A054871 is out of sync on the inputs, the series nevertheless matches what we're discussing here.)
I want to pause here to point out that multiplication grows more quickly than addition. Look at the first few terms of F₁:
- F₁(3,1)=3
- F₁(3,2)=3+3=6
- F₁(3,3)=3+3+3=9
Then compare to the first few terms of F₂:
- F₂(3,1)=3
- F₂(3,2)=3*3=9
- F₂(3,3)=3*3*3=27
What's important here isn't that 27>9. What's important is that the latter function is growing more quickly than the previous one.
We can keep going to F₃, which uses the exponentiation operation. This is as high as most high school math classes go. F₃=3^3^3=19683. The first few terms of F₃ are:
- F₃(3,1)=3
- F₃(3,2)=3^3=27
- F₃(3,3)=3^3^3=19683
You can see that each subsequent function is growing more and more quickly, such that the only the third term, Fₓ(3,3), is fast approaching really big numbers.
Next in the series is F₄, which uses
tetration. F₄=3⇈3⇈3=7,625,597,484,987. Here I am using Knuth arrow notation for the operator symbol, but the idea is the same as all the previous operations. Addition is repeated counting. Multiplication is repeated addition. Exponentiation is repeated multiplication. Tetration is repeated exponentiation. In other words:
- Multiplication is repeated addition:
X*Y = X+X+…+X, where there are Y instances of X in this series.
In the case of F₂(3,2), 3*3=3+3+3.
- Exponentiation is repeated multiplication:
X^Y = X*X*…*X, where there are Y Xs.
3^3=3*3*3
- Tetration is repeated exponentiation:
X⇈Y = X^X^…^X, where there are Y Xs.
3⇈3=3^3^3
Pentation is next: F₅=3↑↑↑3↑↑↑3. It takes a bit of work to figure out this value in simpler terms.
- F₅=3↑↑↑3↑↑↑3
=3↑↑↑(3↑↑↑3)
=3↑↑↑(3⇈3⇈3)
=3↑↑↑(3⇈(3⇈3))
=3↑↑↑(3⇈(7,625,597,484,987))
Remember that tetration is repeated exponentiation, so the part in the parentheses there (3⇈7,625,597,484,987) is 3 raised to the 3 raised to the 3 raised to the 3…raised to the 3, where there are 7,625,597,484,987 instances of 3 in this power tower. The image to the right shows what I mean by a power tower: it's a^a^…^a. In our example, it's 3^3^…^3, with 7,625,597,484,987 threes. And this is just the part in the parentheses. You still have to take 3↑↑↑(N), where N is the huge power tower of threes. It's truly difficult to accurately describe just how big this number truly is.
Fastly Fast
So far I've described the first few functions, F₁, F₂, F₃, F₄, and F₅. These are each associated with an operation. I could go on from pentation to hexation, but instead I want to focus on these increasingly fast growing functions. F₅(3,3) is already mindboggingly huge, so it's difficult to get across how huge F₆(3,3) is in comparison. Think about the speed at which we get to huge numbers from F₁ to F₂ to F₃, and then realize that this is nothing compared to where you get when you move to F₄. And again how this is absolutely and completely dwarfed by F₅. This happens yet again at F₆. It's not just much bigger. It's not just bigger than F₅ by the hugeness of F₅. It's not twice as big, or 100 times as big, nor even F₅ times as big. (After all, the word "times" denotes puny multiplication.) It's not F₅^F₅ even. Nor F₅⇈F₅. Nor even F₅↑↑↑F₅. No, F₆=3⇈⇈3⇈⇈3=3⇈⇈(F₅(3,3)). I literally cannot stress how freakishly massive this number is. And yet: it is just F₆.
This is why I wanted to focus on fast growing functions. Each subsequent function is MUCH bigger than the last, in such a way that the previous number basically approximates to zero. So imagine the size of the numbers as we move along to faster and faster growing functions.
These functions grow fast because they use recursion. Each subsequent function is doing what the last function did, but does it repeatedly. In our case, Fₓ(3,3) is just taking the previous value and using the next highest operator on it. F₂(3,3)=3*F₁(3,3). F₃(3,3)=3^F₂(3,3). F₄(3,3)=3⇈F₃(3,3). F₅(3,3)=3↑↑↑F₄(3,3). And as we saw two paragraphs ago, F₆(3,3)=3⇈⇈F₅(3,3).
I chose this recursive series of functions because I wanted to match up with the examples I used in
my previous discussion of really big numbers. But most mathematicians use the fast growing hierarchy to describe this kind of thing. Think of it as a yardstick against which we can compare other fast growing functions.
Fast Growing Hierarchy
We start with F₀(n)=n+1. This is a new function, unrelated to the multiple input function we've used earlier in this blog post. F₀(n) is the first rung of the fast growing hierarchy. If you want to consider a specific number associated with each rung of the hierarchy, we might choose n=3. So F₀(3)=3+1=4.
We then use recursion to define each subsequent function in the hierarchy. Fₓ₊₁(n)=Fₓ(Fₓ(…Fₓ(n)…)), where there are n instances of Fₓ.
So F₁(n)=F₀(F₀(…F₀(n)…)), with n F₀s. This is equivalent to n+1+1+…+1, where there are n 1s. This means F₁(n)=n+n=2n. In our example, F₁(3)=6.
Next is F₂(n)=F₁(F₁(…F₁(n)…)), with n F₁s. This is just 2*2*…*2*n, with n 2s. So F₂(n)=n2^n. In our example, F₂(3)=3*(2^3)=24.
At each step in the hierarchy, we roughly increase to the next level of operation each time. F₀ is basically addition; F₁ is multiplication; F₂ is exponentiation. It's not exact, but it's in the same ballpark. This corresponds closely to the function I defined earlier in this blog post. Mathematicians use the fast growing hierarchy to give an estimate of how big other functions are. My F₂(3,3) from earlier is roughly F₂(n) in the FGH. (F₂(3,3)=27, while F₂(3)=24.) (Egads, do I regret using F for both functions, even though it should be clear since one has multiple inputs.)
Diagonalization
So at this point you probably get the gist of the fast growing hierarchy for F₂, F₃, F₆, etc. Even though they are mind-boggingly large numbers, you may be able to grasp what we mean we talk about F₉, or F₉₉. These functions grow faster and faster as you go along the series of functions, and there's an infinite number of functions in the list. We can talk about Fₓ with the subscript x being a googol, or 3↑↑↑3↑↑↑3. These functions grow fast. But we can do even better.
Let's define F𝜔(n) as Fn(n). (Forgive the lack of subscripts here; we're about to get complex on what's down there.) Now our input n is going to be used not just as the input in the function, but also as the FGH rank of a function that we already defined above. So, in our example, F𝜔(3)=F₃(3)=F₂(F₂(F₂(3)))=F₂(F₂(24))=F₂(24(2^24))=F₂(24(16777216))=F₂(402653184)= 402653184*(2^402653184)≈10^120000000.
As you can see, F𝜔(n) grows incredibly quickly. More quickly, in fact, than any integer value of Fₓ(n). This means that the sequence of functions I've been talking about previously in this blog post can't even get close to the fast growing F𝜔(n), even though there are infinite integer values you could plug in for Fₓ. An example of a famous function that grows at this level would be the
Ackermann function.
But we can keep going. Consider F𝜔₊₁(n), which is defined exactly as we defined the FGH earlier. F𝜔₊₁(n)=F𝜔(F𝜔(…F𝜔(n)…)), where there are n F𝜔s. This grows faster than F𝜔(n) in a way that is exceedingly difficult to describe. Remember that each function in this sequence grows so much faster than the previous function so as to make it approximate zero for a given input. An example of a famous function that grows at this level would be Graham's function, of which
Graham's number is oft cited as a particularly large number. In particular, F𝜔₊₁(64)>G₆₄.
There's no reason to stop now. We can do F𝜔₊₂(n) or F𝜔₊₆(n) or, in general, F𝜔₊ₐ(n), where a can be any natural number, as high as you might please. You can use a=googol or a=3↑↑↑3↑↑↑3 or even a=F𝜔(3↑↑↑3↑↑↑3). But none of these would be as large as if we introduced a new definition: F𝜔*₂(n)=F𝜔₊n(n). This is defined in exactly the same way that we originally defined F𝜔(n), where the input not only goes into the function, but also into the FGH rank of the function itself. F𝜔*₂(n) grows even faster than any F𝜔₊ₐ(n), regardless of what value you enter in as a.
I'm sure you see by now where this is going. We have F𝜔*₂₊₁(n) next, and so on and so forth, until we get F𝜔*₂₊ₐ(n), with an arbitrarily large a. Then we diagonalize again to get F𝜔*₃(n), and then the family of F𝜔*₃₊ₐ(n). This can on indefinitely, until we get to F𝜔*ₑ₊ₐ(n), where e can be arbitrarily large. A further diagonalization can then be used to create F𝜔*𝜔(n)=F𝜔²(n), which grows faster than F𝜔*ₑ₊ₐ(n) for any combination of e and a.
Yet F𝜔²(n) isn't a stopping point for us. Beyond F𝜔²₊₁(n) lies F𝜔²₊ₐ(n), beyond which is F𝜔²₊𝜔(n), beyond which is the F𝜔²₊𝜔₊ₐ(n) family, and so on, and so forth, past 𝜔²₊𝜔*₂(n), beyond 𝜔²₊𝜔*ₑ₊ₐ(n), all the way to F𝜔³(n). At each step, the functions grow so fast that they completely and utterly dwarf the function before it, and yet we've counted up several times to infinity in this sequence, an infinite number of times, and then did this three times in order to get to F𝜔³(n). These functions grow fast.
Still, there's more to consider. F𝜔
³(n) is followed by F𝜔
⁴(n), all the way up to F𝜔
ⁿ(n), beyond which lies yet another digonalization to get to F𝜔
^𝜔(n). From here, you can just redo all the above: F𝜔
^𝜔₊ₐ(n) to F𝜔
^𝜔₊𝜔₊ₐ(n) to F𝜔
^𝜔₊₂𝜔₊ₐ(n) to F𝜔
^𝜔₊ₑ𝜔₊ₐ(n) until we have to rediagonalize to F𝜔⇈𝜔(n), which we set equal to Fₑ₀(n) just for the purpose of making it easier to read. There are two famous examples of functions that grow at this level of the FGH: the function G(n) = "the length of the
Goodstein sequence starting from n" and the function H(n) = "the maximum length of any
Kirby-Paris hydra game starting from a hydra with n heads" are both at the FGH rank of Fₑ₀(n).
You can keep going, obviously. Tetration isn't the end for 𝜔. We can do Fₑ₀₊₁(n), then the whole family of Fₑ₀₊ₐ(n), followed by Fₑ₁(n). And we can keep going, to Fₑ₂(n) and beyond, increasing the exponent arbitrarily large, followed by Fₑ𝜔(n). And this ride just doesn't stop, because you go through the whole infinite sequence of infinite sequences of infinite sequences of infinite sequences of infinite sequences yet again, increasing the subscript of e to the absurd point of ε₀. And then we can repeat that, and repeat again, and again, infinitely many times, creating a subscript tower where ε has a subscript of ε to the subscript of ε to the subscript of ε to the suscript of… -- infinitely many times. At this point the notation gets too unwieldy yet again, so we move on to using another greek letter: 𝛇, where it starts all over again. And we can do this infinite recursion infinitely yet again, until we have a subscript tower of 𝛇s, after which we can call the next function in the series η.
Each Greek letter represents an absolutely humongous jump, from 𝜔 to ε to 𝛇 to η. But as you can see it gets increasingly complicated to talk about these FGH functions. Enter the Veblen Hierarchy.
Veblen Hierarchy
The Veblen Hierarchy starts with 𝜙₀(a)=𝜔
a, then increases with each subscript to a new greek letter from before. So:
- 𝜙₀(a)=𝜔a
- 𝜙₁(a)= εa
- 𝜙₂(a)= 𝛇a
- 𝜙₃(a)= ηa
This FGH grows much faster than the previous one, because it skips over all the infinite recursions to the final tetration of each greek letter, which it defines as the next greek letter in the series. The Veblen Hierarchy grows fast.
The subscript can get bigger and bigger, reaching 𝜙ₑ(a), where e is arbitrarily large. You can follow this by making 𝜔 the next subscript in the series, then follow the same recursive expansion as before until you get to 𝜔⇈𝜔, which we'd define as ε. And go through the greek letters, one by one, until you've gone through an infinite number of them, after which we can use 𝜙 as the subscript for 𝜙. Then do this again and again, nesting additional 𝜙 as the subscript for each 𝜙, until you have an infinite subscript tower of 𝜙, after which you have to substitute a new notation: Γ₀.
Here we finally reach a new limit. Γ₀ is as far as you can go by using recursion and diagonalization. It's the point at which we've recursed as much as we can recurse, and diagonalized as much as we can diagonalize.
But we can go further.
We can already see Γ₀ as 𝜙(a,0)=a. Let's extend Veblen function notation by defining 𝜙(1,0,0)=γ₀. Adding this extra variable let's us go beyond all the recursion and diagonalization we could do previously. Now we have all of that, and can just add 1.
Let's explore this sequence:
- γ₀=𝜙(1,0,0) Start here.
- γ₁=𝜙(1,0,1) Increment the last digit repeatedly.
- γ𝜔=𝜙(1,0,𝜔) Eventually you reach 𝜔.
After this, the next ordinal is 𝜙(1,1,0). As you can see, we have a new variable to work with. We can keep incrementing the right digit until we get to 𝜔 again, after which we reach 𝜙(1,2,0). And we can do this again and again, until we reach 𝜙(1,𝜔,0). Then the next ordinal would be 𝜙(2,0,0). And we can keep going, more and more until we get to 𝜙(𝜔,𝜔,𝜔). At this point, we're stuck again.
That is, until we add an additional variable.
So now we have 𝜙(1,0,0,0) as the next ordinal. And we can max this out again until we need to add yet another variable, and then yet another variable, and so on, until we have infinite variables. This is called the Small Veblen Ordinal.
ψ(ΩΩω)=φ(1,0,⋯,0⏟ω)
Among FGH functions, the Small Veblen Ordinal ranks in just the lower attic of
Cantor's Attic. It's not even the fastest growing function on the page it's listed on. We're nowhere near the top, despite all this work. Of course, there isn't a top -- not really. But what I mean is that we're nowhere near the top of what mathematicians talk about when they work with really large ordinals.
…and Beyond!
You might notice that at no point did I mention TREE(3), which was one of the numbers I brought up in my last blog post. That's because the TREE() function is way beyond what I've written here. You have to keep climbing, adding new ways of getting to faster and faster growing functions before you reach anything like
TREE(3). And beyond that to the point of absurdity is
SSCG(3). And these are all still vastly beneath the Church Kleene Ordinal, which (despite being countable) is uncomputable. This is where you finally run into the Busy Beaver function. The distances between each of these functions that I've mentioned in this paragraph are absurdly long. It took this long to explain up to the Small Veblen Ordinal, and yet it would take equally long to get up to the TREE() function. And then just as long to get to SSCG(). And just as long to Busy Beaver.
I want to be clear: I'm not saying they are equal distances from each other. I'm saying that it would take an equal amount of time to explain them. At each step of my explanation, I've gotten to absurdly faster and faster growing functions, leaping from concept to concept more quickly than I had any right to. And I would explain that much faster if I kept going, using shorthand to handwave away huge jumps in logic. And yet it would still take that long to explain up to these points.